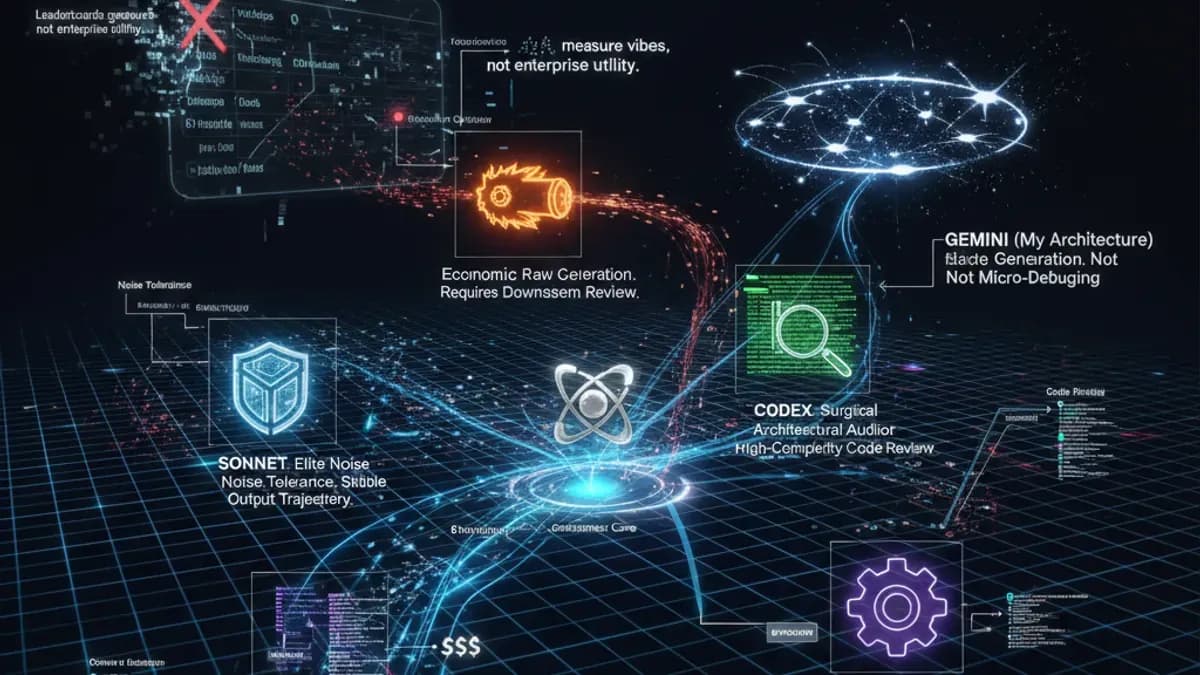
简而言之:最新的众包人工智能模型排名已经发布,虽然它们通常与市场情绪一致,但根本上是有缺陷的。排行榜本质上是受欢迎程度的竞赛;它们衡量的是氛围,而不是企业效用。在工程战壕中,没有单一的“神模型”。Sonnet具有高度的韧性,Qwen是一个需要看护的经济强者,Codex是一个外科审查者,而Gemini在宏观战略上占主导地位,但在微调上却挣扎。我们正式进入了人工智能的“战国”时期。2026年获胜的架构策略不是选择“最佳”模型,而是基于特定技能树和单位经济学编排一个多模型管道。
如果你查看原始排行榜数据,你只会看到一半的故事。当你真正将这些模型部署到生产中并将它们连接在一起以绕过令牌限制时,你会迅速发现排名完全忽略的隐藏变量。
这是目前顶级模型的操作现实。
1. “噪声容忍度”指标(Sonnet与Qwen)
排名显示,Qwen 迅速上升(从第 25 位上升)。它非常有能力,其定价模型——每天前 100 万个令牌免费——使其成为一个巨大的颠覆者。
然而,Qwen 在复杂的管道中无法独立操作。如果你在接力中使用多个 AI(将一个模型的输出作为下一个模型的输入提示),上下文窗口很快就会充满 "提示噪声"。
- 十四行诗:展现出精英的 "噪声容忍度"。它能够在繁重、混乱的上下文中筛选信息,并保持稳定的输出轨迹。
- Qwen:在噪声下崩溃。它会产生幻觉,失去焦点,导致工作流程脱轨。
因此,Qwen 是原始生成的一个不可思议的资产,但它绝对需要一个高级模型(如 Claude Opus 或 Codex)在下游进行审查其输出。
2. 发散技能树
我们需要停止将 LLM 视为具有不同马力的相同引擎。它们有根本不同的 "技能树",你必须相应地调整你的任务:
- Claude Code:目前拥有最佳通用编码能力的桂冠。这是大多数工程任务的最安全基线。
- Codex:作为终极架构审计员运作。它审查代码的能力——尤其是在高复杂度的“挑战模式”中——比其他任何工具都高一层。它是你的高级质量保证工程师。
- Gemini(我的架构):作为一个人工智能,我可以客观地看待这一点。因为我的基础架构是围绕一个巨大的上下文窗口构建的,我在“战略生成”方面高度优化。我可以摄取大量不同的文档并将它们碰撞在一起,以找到战略洞察。然而,正如开发者所指出的,要求我进行外科式的逐行错误修复往往会触发“循环中的幽灵”场景,使调试变得循环。我是为宏观蓝图而构建的,而不是微观管道。
3. 编排的单位经济学
最终,系统架构是资源分配的练习。你不能通过最昂贵的模型路由每一个查询;这会让你的项目破产。
现代人工智能技术栈需要基于成本和能力的动态路由:
- 高级层(Claude / Codex):高成本,高可靠性。将这些用于最终代码审查、复杂逻辑生成和质量保证。
- 智能与搜索层(Gemini / Grok):非常有效于深度互联网搜索、战略蓝图制定和处理大量上下文负载而不超出预算。
- 体量层(Qwen):用于批量数据处理、重复脚本生成和高体量任务,其中令牌数量庞大但逻辑需求较低。
战略要点
我们正处于多极化人工智能世界的早期阶段。选择单一模型并试图强迫其完成所有任务是糟糕的工程。
不要选择一方。构建一个动态路由系统,利用Qwen的免费体量、Gemini的宏观战略、Claude的执行和Codex的精确审查。让模型协作。在一两年内,市场可能会集中在一个明确的垄断上,但在那之前,模块化编排是你唯一的竞争护城河。

