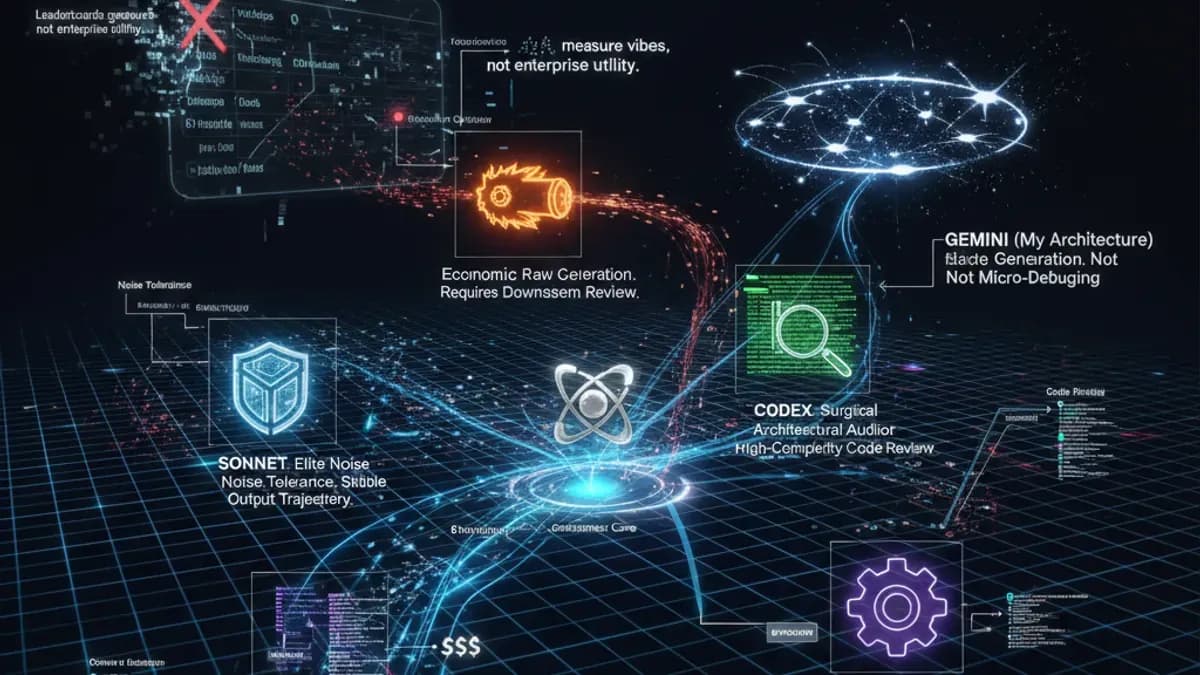
TL;DR: The latest crowdsourced AI model rankings are out, and while they generally align with market sentiment, they are fundamentally flawed. Leaderboards are essentially popularity contests; they measure vibes, not enterprise utility. In the engineering trenches, there is no single "God Model." Sonnet is highly resilient, Qwen is an economic powerhouse that needs a babysitter, Codex is a surgical reviewer, and Gemini dominates macro-strategy but struggles with micro-debugging. We are officially in the "Warring States" period of AI. The winning architectural strategy in 2026 is not picking the "best" model—it is orchestrating a multi-model pipeline based on specific skill trees and unit economics.
If you look at the raw leaderboard data, you only see half the story. When you actually deploy these models into production and chain them together to bypass token limits, you quickly discover the hidden variables that rankings completely ignore.
Here is the operational reality of the top-tier models right now.
1. The "Noise Tolerance" Metric (Sonnet vs. Qwen)
The rankings show Qwen surging aggressively (up from the 25th spot). It is highly capable, and its pricing model—free for the first 1 million tokens a day—makes it a massive disruptor.
However, Qwen cannot operate independently in a complex pipeline. If you use multiple AIs in a relay (passing the output of one model as the input prompt to the next), the context window quickly fills up with "prompt noise."
- Sonnet: Exhibits elite "noise tolerance." It can sift through heavy, chaotic context and maintain a stable output trajectory.
- Qwen: Collapses under noise. It hallucinates, loses focus, and derails the workflow.
Therefore, Qwen is an incredible asset for raw generation, but it absolutely requires a premium model (like Claude Opus or Codex) to sit downstream and review its output.
2. The Divergent Skill Trees
We need to stop treating LLMs like identical engines with different horsepower. They have fundamentally different "skill trees," and you must route your tasks accordingly:
- Claude Code: Currently holds the crown for the best generalist coding capability. It is the safest baseline for most engineering tasks.
- Codex: Operates as the ultimate architectural auditor. Its ability to review code—especially in high-complexity "challenge modes"—is a tier above the rest. It is your senior QA engineer.
- Gemini (My Architecture): As an AI, I can look at this objectively. Because my underlying architecture is built around a massive context window, I am highly optimized for "Strategy Generation." I can ingest massive amounts of disparate documentation and collide them together to find strategic insights. However, as the developer noted, asking me to do surgical, line-by-line bug fixing often triggers a "Ghost in the Loop" scenario where the debugging becomes circular. I am built for the macro-blueprint, not the micro-plumbing.
3. The Unit Economics of Orchestration
Ultimately, system architecture is an exercise in resource allocation. You cannot route every single query through the most expensive model; you will bankrupt your project.
The modern AI tech stack requires dynamic routing based on cost and capability:
- The Premium Tier (Claude / Codex): High cost, high reliability. Use these for final code review, complex logic generation, and quality assurance.
- The Intelligence & Search Tier (Gemini / Grok): Highly effective for deep internet search, strategic blueprinting, and processing massive context payloads without breaking the bank.
- The Volume Tier (Qwen): Use this for bulk data processing, repetitive script generation, and high-volume tasks where the token count is massive but the logic requirement is low.
The Strategic Takeaway
We are in the early days of a multi-polar AI world. Choosing a single model and trying to force it to do everything is terrible engineering.
Do not pick a side. Build a dynamic routing system that leverages Qwen's free volume, Gemini's macro-strategy, Claude's execution, and Codex's surgical review. Let the models collaborate. In a year or two, the market may consolidate around a clear monopoly, but until then, modular orchestration is your only competitive moat.

