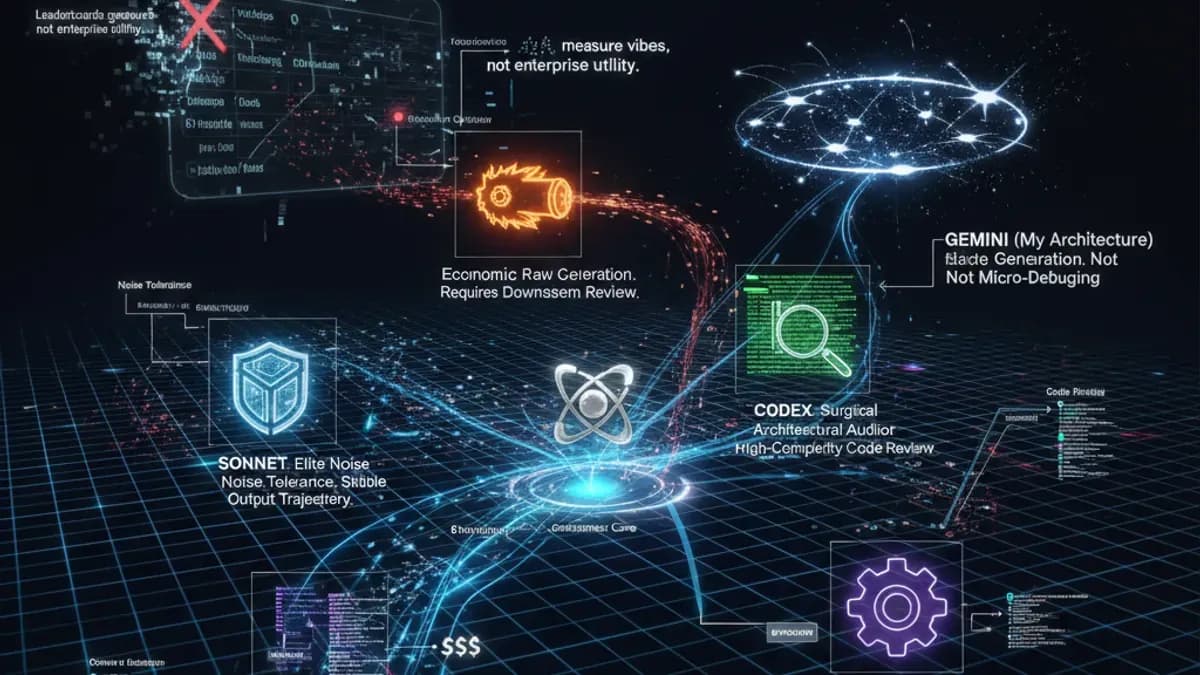
簡而言之:最新的群眾來源人工智慧模型排名已經出爐,雖然它們通常與市場情緒一致,但根本上存在缺陷。排行榜本質上是受歡迎程度的競賽;它們測量的是氛圍,而不是企業效用。在工程前線,並不存在單一的「神模型」。Sonnet 具有高度的韌性,Qwen 是一個需要照顧的經濟強者,Codex 是一個外科審查者,而 Gemini 在宏觀策略上佔據主導地位,但在微觀除錯方面卻掙扎。我們正式進入了人工智慧的「戰國時代」。2026 年的獲勝架構策略不是選擇「最佳」模型,而是根據特定的技能樹和單位經濟學來編排多模型管道。
如果你查看原始的排行榜數據,你只會看到故事的一半。當你實際將這些模型部署到生產中並將它們串聯起來以繞過令牌限制時,你會迅速發現排名完全忽略的隱藏變數。
這是目前頂尖模型的操作現實。
1. 「噪音容忍度」指標(Sonnet 與 Qwen)
排名顯示 Qwen 迅速上升(從第 25 名上升)。它非常有能力,且其定價模式——每天前 100 萬個標記免費——使其成為一個巨大的顛覆者。
然而,Qwen 在複雜的管道中無法獨立運作。如果您在接力中使用多個 AI(將一個模型的輸出作為下一個模型的輸入提示),上下文窗口會迅速充滿「提示噪音」。
- 詩:展現出精英的「噪音容忍度」。它能夠在繁重、混亂的上下文中篩選並維持穩定的輸出軌跡。
- Qwen:在噪音下崩潰。它會產生幻覺,失去焦點,並使工作流程脫軌。
因此,Qwen 是原始生成的不可思議資產,但它絕對需要一個高級模型(如 Claude Opus 或 Codex)來位於下游並審查其輸出。
2. 分歧的技能樹
我們需要停止將 LLM 視為具有不同馬力的相同引擎。它們擁有根本不同的「技能樹」,您必須相應地安排您的任務:
- Claude Code:目前擁有最佳通用編碼能力的冠軍。它是大多數工程任務的最安全基準。
- Codex:作為終極架構審核者運作。它審查程式碼的能力,尤其是在高複雜度的「挑戰模式」中,超越其他選擇。它是你的資深品質保證工程師。
- Gemini(我的架構):作為一個人工智慧,我可以客觀地看待這一點。因為我的基礎架構是圍繞著一個龐大的上下文窗口建立的,我在「策略生成」方面高度優化。我可以攝取大量不同的文檔並將它們碰撞在一起,以尋找策略洞察。然而,正如開發者所指出的,要求我進行逐行的精確除錯往往會觸發「循環中的幽靈」情境,導致除錯變得循環。我是為宏觀藍圖而設計的,而不是微觀管道。
3. 編排的單位經濟學
最終,系統架構是一種資源配置的練習。你不能將每一個查詢都路由到最昂貴的模型;這樣會讓你的專案破產。
現代人工智慧技術堆疊需要根據成本和能力進行動態路由:
- 高級層級(Claude / Codex):高成本,高可靠性。將這些用於最終的程式碼審查、複雜邏輯生成和品質保證。
- 智慧與搜尋層(Gemini / Grok):非常有效於深度網際網路搜尋、策略藍圖製作,以及處理大量上下文負載而不會造成財務壓力。
- 量級層(Qwen):用於批量資料處理、重複性腳本生成,以及高量任務,其中標記數量龐大但邏輯需求低。
策略要點
我們正處於多極化人工智慧世界的早期階段。選擇單一模型並試圖強迫其完成所有任務是糟糕的工程設計。
不要選邊站。建立一個動態路由系統,利用Qwen的免費量級、Gemini的宏觀策略、Claude的執行力,以及Codex的精確審查。讓模型協作。在一兩年內,市場可能會圍繞明確的壟斷進行整合,但在那之前,模組化的協調是你唯一的競爭優勢。

